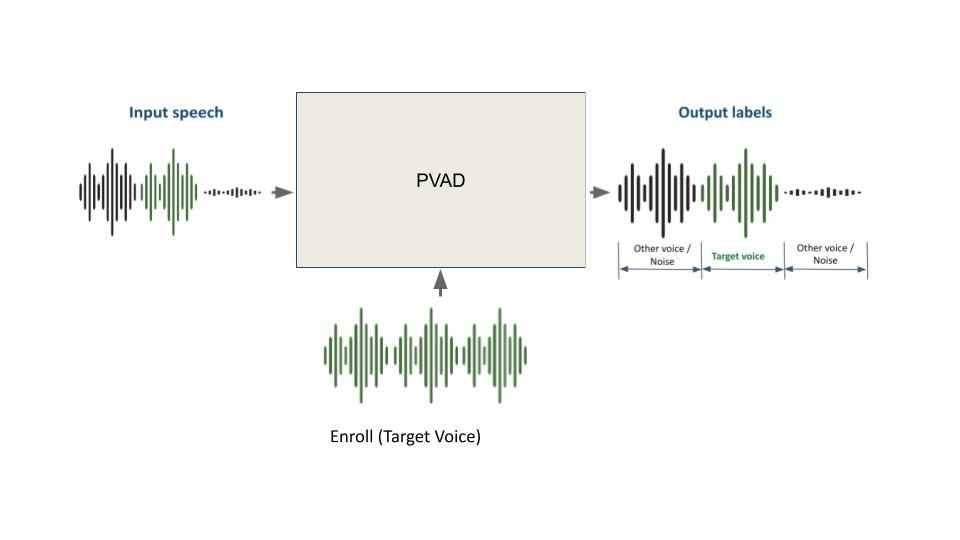
Нейросетевая модель на основе сверточных нейронных сетей, которая позволяет выделять речь целевого спикера в потоке и подавлять речь других людей.
Задачи
Для системы голосового общения в условиях зашумленности (Cocktail Party Challenge - когда одновременно слышно речь множества людей) на основе образца речи:
- обеспечить выделение речи целевого спикера;
- удалить шумы;
- удалить постороннюю речь;
- воспроизвести SOTA шумоочистку без выделения целевого спикера.
Решение
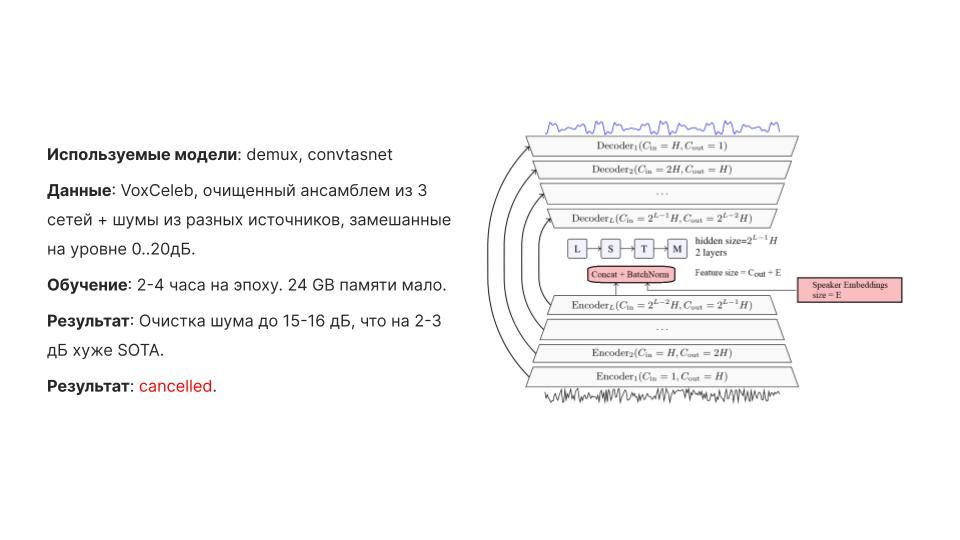
В ходе работы были проведены эксперименты на следующих моделях: модель end-to-end шумоочистки со встроенным распознаванием целевого спикера. В качестве основы использовались DEMUCS, во внутренние слои которого мы подавали эмбеддинги речи целевого спикера. модель personalized voice activity detection - для выделения фрагментов (10-80 миллисекунд) речи, где присутствует речь целевого спикера. SOTA шумоочистка без выделения целевого спикера - нам не удалось добиться результатов, сопоставимых с опубликованными и достигнутыми нашим заказчиком (делали мы около 3 месяцев, заказчик решал задачу несколько лет).
Для исследования использовались два вида данных: Публичные датасеты (LibriSpeech, VoxCeleb2, и другие) - общий объем данных превышал 1 Тб, по части экспериментов делалась предобработка датасетов (конвертация, аугментация), которая длилась больше 10 часов на nvme SSD диске Небольшие датасеты от заказчика (использовались для тестирования)
В ходе проекта было проведено более 100 экспериментов с различными параметрами моделей и процесса обучения. Были периоды, когда мы по несколько дней и недель непрерывно обучали на 3 машинах модели с различными параметрами.
Этап 1 (Phase 2) (21.10.20 – 28.02.21): PVAD: near-field EER < 5%, far-field EER < 10%; Denoiser: найти данные, найти модели, обучить.
Этап 2 (Phase 3) (01.03.19 – 30.04.21): PVAD: Улучшение на тесте конечного заказчика (Delivery test) Denoiser: сделать как у SOTA (18 dB)
Этап 3 (Demo preparation) (01.05.21 – 30.09.21): PVAD: Исправление демки на телефоне Denoiser: cancelled